Keywords: Metodi Monte Carlo, pricing.
Le citazioni del presente articolo sono ottenute mediante il comando unix fortune -a -m random e fortune -a -m chance.
Questo tutorial vuole presentare alcuni aspetti dei metodi Monte Carlo (MMC), con particolare enfasi sulle applicazioni di prezzaggio di titoli finanziari. La trattazione sarà forzatamente sbrigativa, sia per il poco spazio disponibile che per la vastità del materiale scientifico prodotto in questi ultimi anni. Alcuni degli sviluppi più recenti saranno illustrati in un'altra lezione di questa scuola.
Nella sezione successiva saranno dati alcuni cenni storici sul MMC e, in particolare, sulle applicazioni finanziarie. La sezione 3 descrive le basi statistiche e matematiche dei MMC. L'interpretazione del metodo alla luce dell teorema del limite centrale è alla base dell'uso di numeri pseudocasuali. D'altro canto l'osservazione che l'uso della simulazione MC equivale alla valutazione di un integrale, apre la strada a tecniche che sono sfociate, ad esempio, nell'utilizzo di numeri quasi-casuali. Nella sezione 4 discuteremo della generazione di numeri casuali dando anche un breve e non esaustivo elenco dei più diffusi generatori di numeri casuali. La generazione di numeri casuali normalmente distribuiti assume una particolare importanza nell'ambito di problemi di prezzaggio, vista l'ubiquità dell'ipotesi di passeggiata lognormale dei prezzi. La sezione 5 descrive la tecnica di prezzaggio mediante generazione di payoff corretti per il rischio. Infine, nell'ultima sezione si affronta il tema della riduzione della varianza. In maggior dettaglio, illustreremo la tecnica delle variabili antitetiche, di facile e ampio utilizzo, e delle variabili di controllo.
Only God can make random selections.
La versione più diffusa sulle origini del MMC le fa risalire ai primi anni 40, quando J. Von Neumann lavorava nei laboratori di Los Alamos. Nella simulazione di sistemi nucleari complessi si utilizzarono per la prima volta numeri ``casuali''. Il nome del metodo fu coniato ricordando la sede del celebre casinò, regno per antonomasia del caso.
N. Metropolis però, citando una conversazione con E. Segre in [Metropolis, 1987], racconta che E. Fermi ``inventò il MMC quando stava studiando come moderare i neuroni a Roma. Non pubblicò nulla sull'argomento, ma usò il metodo per risolere molti problemi con ogni tipo di macchina di calcolo a disposizione... Fermi si compiaceva di stupire i colleghi con previsioni estremamente accurate di risultati sperimentali. Rivelò infine che le sue ``stime" erano ottenute con tecniche di campionamento statistico impiegate nelle ore di insonnia. E così Fermi aveva indipendentemente sviluppato il MMC quasi 15 anni prima (di Von Neumann)". La storia appare credibile tenendo conto delle leggendarie capacità intellettuali di Fermi e considerando che Metropolis stesso, inventore di un celebre algoritmo di campionamento che porta il suo nome, lavorò a Los Alamos nel gruppo di Von Neumann.
Nella prima applicazione finanziaria del 1977 ([Boyle, 1977]) si presenta un metodo per la valutazione di opzioni europee (anche in presenza di dividendi). Fin dall'articolo di Boyle si coglie come la velocità del metodo possa risultare insoddisfacente e il prezzo dell'opzione scritta su un titolo che non paga dividendi, calcolabile con la formula di Black-Scholes, è usato per ridurre la varianza del prezzo dell'opzione in presenza di dividendi.
Nel 1990, Kemna e Vorst affrontano con successo il problema di valutare un'opzione asiatica il cui payoff dipende da una media aritmetica di prezzi, . Il risultato è significativo perché non è nota una formula chiusa di valutazione per questo tipo di prodotto finanziario derivato. Anche in questo caso, la varianza della stima prodotta è ridotta mediante l'uso di una variabile di controllo. Nel caso specifico, si tratta del prezzo di una opzione con payoff dipendente dalla media geometrica dei prezzi per cui è nota una formula analitica di valutazione.
Il successo ottenuto nel prezzaggio di opzioni asiatiche rende palese che MMC è particolarmente appropriato per opzioni europee e path-dependent (cioè il cui payoff dipende dall'intera traiettoria dei prezzi e non solo dal valore finale del sottostante). Nel corso degli anni `90 il numero di articoli dedicati ad applicazioni finanziarie di MMC diventa enorme. In molti casi, essenzialmente riconducibili a opzioni dipendenti da molti fonti di rischio (titoli, tassi d'interesse o di cambio...), si tratta dell'unico metodo in grado di produrre delle valutazioni approssimate, pur con necessità di calcolo talvolta massicce. Altri metodi, basati su alberi o sulla risoluzione di equazioni differenziali alle derivate parziali, sono infatti applicabili con notevoli difficoltà teoriche e pratiche al caso di 3 o più fonti di rischio. L'impiego dei MMC è invece poco sensibile al problema della dimensionalità, almeno per quanto riguarda la fase di programmazione, essendo sufficiente generare vettori di numeri casuali piuttosto che singole variabili casuali. Inoltre, l'ordine di convergenza del MMC è indipendente dalla dimensione del problema. È tuttavia ovvio che risolvere un problema multidimensionale è computazionalmente più costoso di un semplice problema monodimensionale, non fosse altro che per il maggior costo di generare tutte le componenti del vettore casuale.
In [Boyle et al., 1997] si puø trovare una panoramica delle recenti applicazioni finanziarie dei MMC.
If the odds are a million to one against something occurring, chances are 50-50 it will.
Il fondamento statistico dei MMC è il teorema del limite centrale, che assicura che la media di N variabili casuali indipendenti e identicamente distribuite con media m si distribuisce approssimativamente in modo normale, con media m e varianza tendente a zero con N. Formalmente:
Proposition 1 Sia
X1,¼,XN,¼ una successione di variabili casuali
indipendenti e identicamente distribuite,
E[Xi] = m,Var[Xi] = s2, i = 1,¼,¥.
SN® N
æ
ç
è
m,
s2
N
ö
÷
ø
,
Le ipotesi del teorema possono essere notevolmente indebolite, ad esempio consentendo blanda correlazione fra le X. Se identifichiamo la variabile Xi con il `payoff' del titolo derivato all'i-esima simulazione, possiamo evidenziare i seguenti punti:
Il termine payoff appare fra virgolette perché non si tratta del payoff fisico ma di una sua versione corretta per il rischio, come vedremo in seguito. Per il momento osserviamo che dopo un momento di iniziale entusiasmo, il quarto punto appena esposto merita una ulteriore riflessione critica. Supponiamo che la precisione della stima sia misurata dalla sua deviazione standard (tanto miniore è, tanto meglio). Se è vero che aumentando N la deviazione standard diminuisce tendendo a zero, è pur sempre vero che la velocità di convergenza è molto lenta. Poiché la deviazione standard tende a zero con 1/ÖN, per dimezzare l'errore bisogna quadruplicare il numero di simulazioni e quindi, si noti bene, anche il tempo di calcolo. Questo significa che l'ottenimento di piccole deviazioni standard potrebbe richiedere tempi di calcolo inaccettabilmente lunghi.
Quanto appena esposto non è perø l'unico modo in cui si puø interpretare il MMC. Il calcolo della media, infatti, si puø descrivere anche in termini diversi. Sia f una funzione integrabile (in termini finanziari, un payoff) e supponiamo per semplicità che sia non nulla solo nell'intervallo [0,1]. Questo non riduce la generalità di quanto andiamo dicendo. Allora possiamo approssimare l'integrale di f con delle somme:
| (3.1) |
|
|
La lezione dei precedenti esempi d'integrazione è che una scelta deterministica e tutt'altro che casuale degli xi puø produrre un grande miglioramento nel calcolo dei prezzi. Alcuni dei metodi che sfruttano questa idea sono detti quasi-Monte Carlo per distinguerli dagli usuali metodi ``statistici''. Qualora sia necessario, per rendere palese la loro casualità si userà il prefisso ``pseudo''.
Anyone attempting to generate random numbers by deterministic means is, of course, living in a state of sin. (John Von Neumann)
Dopo aver brevemente tentato di descrivere i fondamenti del MMC, ci proponiamo in questa sezione di presentare alcuni metodi e algoritmi per la generazione dell'ingrediente base: numeri casuali. La frase citata in apertura mette in evidenza come il proporsi di creare casualità mediante un computer rasenti la follia. Dove sarebbe la casualità di sequenze di numeri generate da un programma completamente deterministico e che è banalmente in grado di riprodurre l'output a piacimento? Qual'è il concetto di caso di cui stiamo parlando? I numeri casuali generati da un computer sono considerati tali perché soddisfano una serie di requisiti statistici di cui godono anche valori autenticamente casuali: risultano statisticamente indistinguibili (per indipendenza, proprietà spettrali e altro) da quello che vogliono imitare. Quindi, se non sono constatabili differenze con sequenze genuinamente stocastiche, questi numeri possono essere considerati casuali. Per mettere in evidenza questo aspetto, sono spesso denominati numeri pseudocasuali.
Il seguente risultato risultato spiega perché la generazione di numeri casuali uniformemente distribuiti sia alla base della produzione di valori aventi anche altre distribuzioni di probabilità continue.
Proposition 1
Sia F funzione di ripartizione continua, invertibile e sia U variabile
casuale uniformemente distribuita nell'intervallo [0,1]. Allora
F-1(U) ~ F,
In sostanza, per generare numeri casuali con distribuzione arbitraria F, basta valutare l'inversa della funzione di ripartizione in corrispondenza di variabili casuali uniformi. Alcuni diffusi generatori di variabili casuali sono di seguito descritti:
| (4.2) |
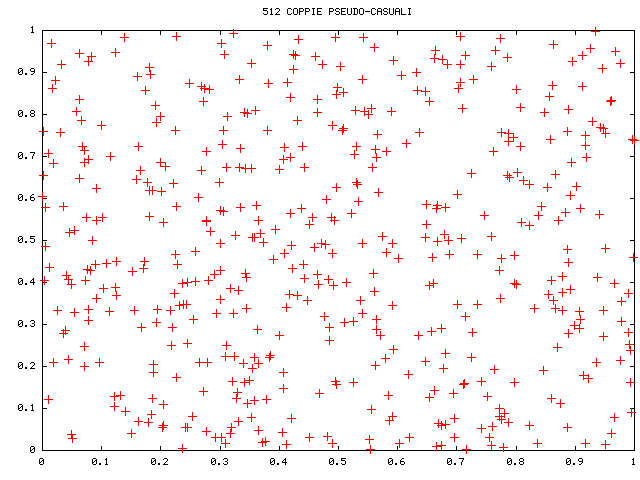
Come accennato nella sezione 3 possiamo cercare di campionare numeri casuali in modo da riempire lo spazio `più uniformemente' di quanto sia possibile con estrazioni pseudocasuali: si pensi ad esempio a punti distribuiti su una griglia mono o bidimensionale, che evidentemente `riempiono meglio' il quadrato unitario: si veda nella Figura 1 una rappresentazione bidimensionale che illustra efficacemente le diverse caratteristiche di punti pseudocasuali e a griglia. L'uso di griglie nella simulazione si scontra con due problemi. Da un lato bisogna fissare a priori la dimensione della griglia con la spiacevole conseguenza che, qualora risultasse necessario aumentare il numero di simulazioni, non è banale evitare di ricalcolare il tutto con una griglia più fine. Dall'altro bisogna tenere conto che il numero di punti in una griglia cresce esponenzialmente nella dimensione dello spazio, producendo rapidamente richieste di calcolo intollerabili.
Esiste tuttavia un modo per generare successioni di numeri ``casuali" di lunghezza non predeterminata: queste successioni sono dette quasi-casuali anche se non vi è nulla di aleatorio ma, al contrario, sono costituite di punti che si posizionano nei buchi lasciati dai punti precendenti. Un semplice esempio è la successione di Halton {Hj},j = 1,¼, ottenibile con la seguente procedura:
|
In sostanza la procedura consiste nel capovolgere le cifre dell'espansione in base b e porre un punto decimale di fronte a quanto ottenuto. Se sono necessari numeri casuali multidimensionali si può procedere generando per ciascuna componente una successione di Halton con radice b diversa. Solitamente si utilizzano in successione i numeri primi (2,3,5,...). Quanto detto graffia appena la superficie dell'argomento e rimandiamo gli interessati a [Joy et al., 1996,Dupire, 1998] e alla bibliografia ivi presente. L'uso di successioni di punti quasi-casuali è appetibile poiché l'integrazione di una funzione smooth f in un dominio n-dimensionale produce un'errore dell'ordine di
|
Nella stragrande maggioranza della applicazioni finanziarie sono necessari dei valori normalmente distribuiti. In questo caso, l'inversione numerica della funzione di ripartizione normale F richiesta nella proposizione 4.1 è non banale. La valutazione di F, si ottiene a partire dalla funzione di errore complementare erfc(x) di cui è nota una eccellente approssimazione (circa 7 cifre decimali corrette), [Press et al., 1992]. Con le posizioni
| (4.3) |
| |||||||||||||||||||
| (4.4) | ||||||||||
| (4.5) |
A questo punto, si procede a determinare numericamente x = F-1(u) risolvendo in x l'equazione u = F(x). Questo algoritmo è , ad esempio, utilizzato dal programma Mathematica nell'implementazione della funzione InverseErf. Si noti che, risolvendo la precedente equazione con il metodo di Newton, la derivata di F, richiesta nell'iterazione
| (4.6) |
Una approssimazione diretta alla funzione F-1 si può trovare in [Moro, 1985].
L'inversione della funzione F non è l'unico modo in cui si possono ottenere numeri casuali normali a partire da valori uniformemente distribuiti: un metodo molto diffuso utilizza una trasformazione, detta di Box-Muller, che produce variabili casuali normali a coppie. Se U1, U2 sono uniformemente distribuite, allora
| (4.7) |
I cannot believe that God plays dice with the cosmos (Albert Einstein, on the randomness of quantum mechanics).
Riprendiamo quanto detto nella sezione 3, quando abbiamo detto che il prezzo di un derivato è pari al valore atteso scontato dei suoi `payoff'. In [Cox et al., 1979] si mostra che, se esiste un portafoglio di copertura per il titolo derivato, allora il prezzo si ottiene come valore atteso, scontato al tasso free-risk, dei payoff neutralizzati rispetto al rischio. Con quest'ultima espressione si intendono i payoff generati da fonti di rischio aventi stesso rendimento medio dell'attività priva di rischio. Più formalmente, sia r l'intensità istantanea di interesse priva di rischio, sia S un titolo (per fissare le idee, un'azione) con rendimento logaritmico normalmente distribuito N(mT,s2T). Ne segue che, detto S0 il prezzo iniziale dell'azione, al tempo T il suo valore è
|
|
D'ora in poi denoteremo tutte le attività con S, omettendo l'apice per semplicità.
Siamo ora in grado di determinare il prezzo [^C]T di un derivato che paga alla scadenza T la somma f(ST). Applicando la formula (3.1) e attualizzando si ottiene
| (5.8) |
Si supponga, ad esempio, di dover valutare una opzione call europea emessa su un titolo azionario che non paga dividendi con volatilità annua s, tasso istantaneo r, valore iniziale S0, prezzo d'esercizio k, scadenza T. Si noti che non è necessario conoscere il drift fisico (m) del titolo. Il prezzo puø essere valutato mediante il calcolo di
|
|
La formula di valutazione (5.8) puø essere utilizzata qualunque sia la funzione di payoff, e si estende facilmente al caso in cui il titolo S paga dividendi con continuità al tasso (istantaneo) d. L'estensione multidimensionale di (5.8) è altrettanto immediata: se f(S1T,¼,SnT) è il payoff di un derivato scritto su n beni azionari, allora il prezzo è dato da
|
We are all agreed that your theory is crazy. The question which divides us is whether it is crazy enough to have a chance of being correct. My own feeling is that it is not crazy enough (Niels Bohr).
Come abbiamo visto, la convergenza del MMC è dell'ordine di N-1/2. Graficamente, se poniamo sull'asse delle ascisse il logaritmo del numero di simulazioni N e sulle ordinate il logaritmo dell'errore medio otteniamo una retta con pendenza -1/2 che è evidente nella linea superiore della Figura 3. Fra i modi per ridurre l'errore possiamo pensare a metodi che riducano la pendenza o il termine noto della retta. Fra i primi ricordiamo l'uso di successioni quasi-casuali che producono pendenze prossime a -1. Fra i secondi tratteremo il metodo delle variabili antitetiche e daremo qualche cenno al metodo delle variabili di controllo. Ribadiamo che, asintoticamente, il MMC e le sue varianti antitetiche e con variabili di controllo producono un errore del medesimo ordine. Nondimeno, i miglioramenti in termini di accuratezza ottenibili con N finito sono talvolta enormi.
Supponiamo di dover valutare mediante simulazione Monte Carlo un titolo europeo con payoff f(S). Equivalentemente il payoff casuale si può pensare come funzione della variabile normale z:
|
| (6.9) |
| (6.10) |
Per semplicità di applicazione e per il suo modesto costo computazionale, il metodo delle varibili antitetiche è molto diffuso.
Un'altra tecnica impiegabile per ridurre la varianza di una simulazione è quella delle variabili di controllo. Supponiamo di poter generare insieme ai valori campionari dei payoff si anche un'altra successione di variabili casuali {yi} positivamente correlati con si e tali che E[ yi] è costante e pari a E[ Y]. Risulta evidente che lo stimatore
| (6.11) |
Tipicamente non c'è un metodo generale per la scelta di una variabile di controllo che spesso è selezionata caso per caso sulla base di specificità del opzione in esame: sia [Boyle, 1977] che [Kemna and Vorst, 1990] utilizzano ad esempio variabili di controllo appositamente definite.
1 Scuola Estiva di Finanza Computazionale - Auronzo di Cadore (BL), 31 maggio - 2 giugno 2000. Email: paolop@unive.it, http://www.dma.unive.it/ ~ paolop.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}